5. Internal communication¶
This page describes how each service in dojot communicate with each other.
5.1. Components¶
Current dojot components are shown in Fig. 5.1.
![[Auth]
[DeviceManager]
[Persister]
[History]
[DataBroker]
[FlowBroker]
package "Databases" {
[mongodb]
[postgreSQL]
}
package "IoT agents" {
[IoT MQTT]
[IoT LoRa]
[IoT sigfox]
[IoT RabbitMQ]
}
[postgreSQL] <-- [Auth]
[postgreSQL] <-- [DeviceManager]
[postgreSQL] <- [Kong]
[mongodb] <- [Persister]
[mongodb] <-- [FlowBroker]
[mongodb] <-- [History]](_images/plantuml-46f094d0779ab40a1836c661c3fb039cb6d16771.png)
Fig. 5.1 dojot components¶
They are:
- Auth: authentication mechanism
- DeviceManager: device and template storage.
- Persister: component that stores all device-generated data.
- History: component that exposes all device-generated data.
- DataBroker: deals with subjects and Kafka topics, as well as socket.io connections.
- Flowbroker: handles flows (both CRUD and flow execution)
- IoT agents: agents for different protocols.
Each service will be briefly described in this page. More information can be found in each component documentation.
5.2. Messaging and authentication¶
There are two methods through which dojot components can talk to each other: via HTTP REST requests and via Kafka. They are intended for different purposes, though.
HTTP requests can be sent at boot time when a component want, for instance, information about particular resources, such as list of devices or tenants. For that, they must know which component has which resource in order to retrieve them correctly. This means - and this is a very important thing that drives architectural choices in dojot - that only a single service is responsible for retrieving data models for a particular resource (note that a service might have multiple instances, though). For example, DeviceManager is responsible for storing and retrieving information model for devices and templates, FlowBroker for flow descriptions, History for historical data, and so on.
Kafka, in the other hand, allows loosely coupled communication between instances of services. This means that a producer (whoever sends a message) does not know which components will receive its message. Furthermore, any consumer doesn’t know who generated the message that it being ingested. This allows data to be transmitted based on “interests”: a consumer is interested in ingesting messages with a particular subject (more on that later) and producers will send messages to all components that are interested in it. Note that this mechanism allows multiple services to emit messages with the same “subject”, as well as multiple services ingesting messages with the same “subject” with no tricky workarounds whatsoever.
5.2.1. Sending HTTP requests¶
In order to send requests via HTTP, a service must create an access token, described here. There is no further considerations beyond following the API description associated to each service. This can be seen in figure Fig. 5.2. Note that all interactions depicted here are abstractions of the actual ones. Also, it should be noted that these interactions are valid only for internal components. Any external service should use Kong as entrypoint.
This is a test

Fig. 5.2 Initial authentication¶
In this figure, a client retrieves an access token for user admin whose password is p4ssw0rd. After that, a user can send a request to HTTP APIs using it. This is shown in Fig. 5.3. Note: the actual authorization mechanism is detailed in Auth + API gateway (Kong).
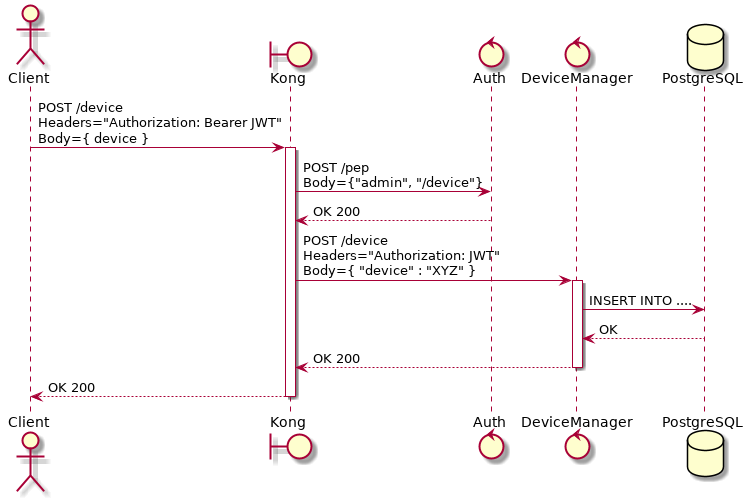
Fig. 5.3 Sending messages to HTTP API¶
In this figure, a client creates a new device using the token retrieved in
Fig. 5.2. This request is analyzed by Kong, which will
invoke Auth to check whether the user set in the token is allowed to POST
to /device endpoint. Only after the approval of such request, Kong will
forward it to DeviceManager.
5.2.2. Sending Kafka messages¶
Kafka uses a quite different approach. Each message should be associated to a subject and a tenant. This is show in Fig. 5.4;
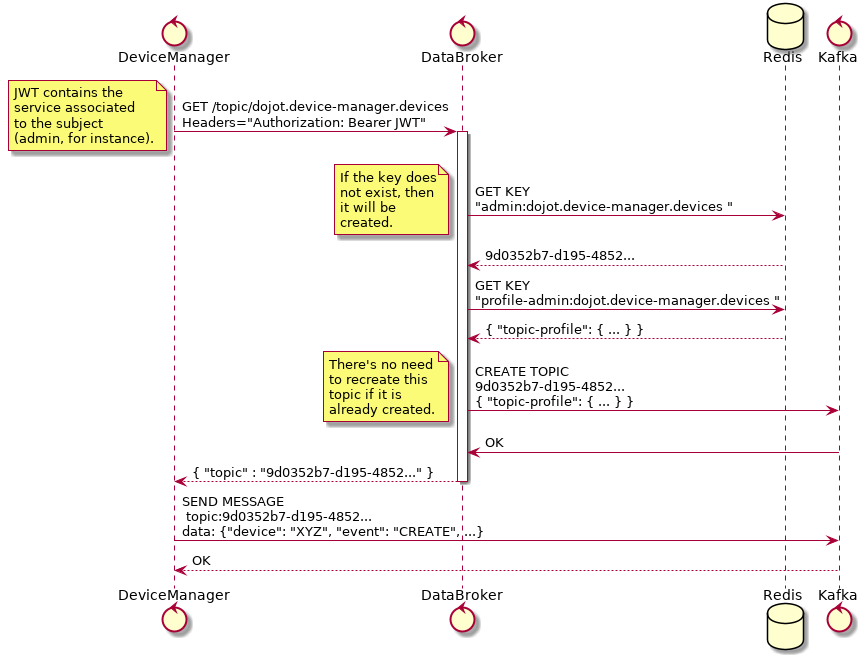
Fig. 5.4 Retrieving Kafka topics¶
In this example, DeviceManager needs to publish a message about a new device.
In order to do so, it sends a request to DataBroker, indicating which tenant
(within JWT token) and which subject (dojot.device-manager.devices) it
wants to use to send the message. DataBroker will invoke Redis to check whether
this topic is already created and check whether dojot administrator had created
a profile to this particular tuple {tenant, subject}.
The two profile schemes available are shown in Fig. 5.5 and Fig. 5.6.

Fig. 5.5 Automatic scheme profile¶
The automatic scheme set the number of Kafka partitions to be used to the topic being created, as well as the replication factor (how many replicas will be there for each topic partition). It’s up to Kafka to decide which partition and replica will be assigned to which broker instance. You can check Kafka partitions and replicas in order to know a bit more about partition and replicas. Of course you can check Kafka’s official documentation.
![class IAssignedScheme <<interface>> {
+ replica_assignment: Map<number, number[]>;
}](_images/plantuml-07331eec038012eaaae89c4e6ab297b577213d4a.png)
Fig. 5.6 Assigned scheme profile¶
The assigned scheme indicates which partition will be allocated to which Kafka instance. This includes also replicas (partitions with more than one associated Kafka instance).
5.2.3. Bootstrapping tenants¶
All components are interested in a set of subjects, which will be used to either send messages or receive messages from Kafka. As dojot groups Kafka topics and tenants into subjects (a subject will be composed by one or more Kafka topics, each one transmitting messages for a particular tenant), the component must bootstrap each tenant before sending or receiving messages. This is done in two phases: component boot time and component runtime.
In the first phase, a component asks Auth in order to retrieve all currently configured tenants. It is interested, let’s say, in consuming messages from device-data and dojot.device-manager.devices subjects. Therefore, it will request DataBroker a topic for each tenant for each subject. With that list of topics, it can create Producers and Consumers to send and receives messages through those topics. This is shown by Fig. 5.7.
![control Component
control Auth
control DataBroker
control Kafka
Component -> DataBroker: GET /topic/dojot.tenancy \nHeaders="Authorization: JWT"
DataBroker --> Component: {"topic" : "eca098e7f..."}
Component-> Auth: GET /tenants
Auth --> Component: {"tenants" : ["admin", "tenant1"]}
loop each tenant
Component -> DataBroker: GET /topic/device-data \nHeaders="Authorization: JWT[tenant]"
DataBroker --> Component: {"topic" : "890874987ef..."}
Component -> Kafka: SUBSCRIBE\ntopic: 890874987ef...
Kafka --> Component: OK
Component -> DataBroker: GET /topic/dojot.device-manager.devices \nHeaders="Authorization: JWT[tenant]"
DataBroker --> Component: {"topic" : "890874987ef..."}
Component -> Kafka: SUBSCRIBE\ntopic: 890874987ef...
Kafka --> Component: OK
end](_images/plantuml-6bee9212b363f450c978b180fd5f14ccc9b84218.png)
Fig. 5.7 Tenant bootstrapping at startup¶
The second phase starts after startup and its purpose is to process all messages received through Kafka. This will include any tenant that is created after all services are up and running. Fig. 5.8 shows how to deal with these messages.
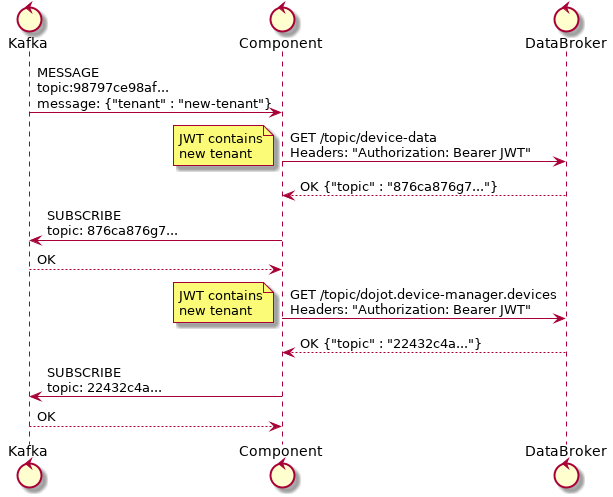
Fig. 5.8 Tenant bootstrapping¶
All services that are somehow interested in using subjects should execute this procedure in order to correctly receive all messages.
5.3. Auth + API gateway (Kong)¶
Auth is a service deeply connected to Kong. It is responsible for user management, authentication and authorization. As such, it is invoked by Kong whenever an request is received by one of its registered endpoints. This section will detail how this is performed and how they work together.
5.3.1. Kong configuration¶
There are two configuration procedures when starting Kong within dojot:
- Migrating existing data
- Registering API endpoints and plugins.
The first task is performed by simply invoking Kong with a special flag.
The second one is performed by executing a configuration script kong.config.sh. Its only purpose is to register endpoints in Kong, such as:
(curl -o /dev/null ${kong}/apis -sS -X POST \
--header "Content-Type: application/json" \
-d @- ) <<PAYLOAD
{
"name": "data-broker",
"uris": ["/device/(.*)/latest", "/subscription"],
"strip_uri": false,
"upstream_url": "http://data-broker:80"
}
PAYLOAD
This command will register the endpoint /device/*/latest and /subscription and all requests to it are going to be forwarded to http//data-broker:80. You can check the documentation on how to add endpoints in Kong’s documentation.
For some of its registered endpoints, kong.config.sh will add two plugins to selected endpoints:
- JWT generation. The documentation for this plugin is available at Kong JWT plugin page.
- Configuration a plugin which will forward all policies requests to Auth. will invoke Auth in order to authenticate requests. This plugin is available in PEP-Kong repository.
The following request install these two plugins in data-broker API:
curl -o /dev/null -sS -X POST ${kong}/apis/data-broker/plugins -d "name=jwt"
curl -o /dev/null -sS -X POST ${kong}/apis/data-broker/plugins -d "name=pepkong" -d "config.pdpUrl=http://auth:5000/pdp"
5.3.1.1. Emitted messages¶
Auth will emit just one message via Kafka for tenant creation:
{
"type" : "CREATE",
"tenant" : "XYZ"
}
5.4. Device Manager¶
DeviceManager stores and retrieves information models for devices and templates and a few static information about them as well. Whenever a device is created, removed or just edited, it will publish a message through Kafka. It depends only on DataBroker and Kafka for reasons already explained in this document.
All messages published by Device Manager to Kafka can be seen in Device Manager messages.
5.5. IoT agent¶
IoT agents receive messages from devices and translate them into a default
message to be published to other components. In order to do that, they might
want to know which devices are created in order to properly filter messages
which are not allowed into dojot (using, for instance, security information to
block messages from unauthorized devices). It will use the device-data
subject and bootstrap tenants as described in Bootstrapping tenants.
After requesting the topics for all tenants within device-data subject, IoT agent will start receiving data from devices. As there are a plethora of ways by which devices can do that, this step won’t be detailed in this section (this is highly dependent on how each IoT agent works). It must, though, send a message to Kafka to inform other components of all new data that the device just sent. This is shown in Fig. 5.9.
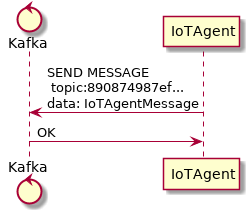
Fig. 5.9 IoT agent message to Kafka¶
The data sent by IoT agent has the structure shown in Fig. 5.10.
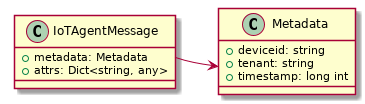
Fig. 5.10 IoT agent message structure¶
Such message would be:
{
"metadata": {
"deviceid": "c6ea4b",
"tenant": "admin",
"timestamp": 1528226137452
},
"attrs": {
"humidity": 60,
"temperature" : 23
}
}
5.6. Persister¶
Persister is a very simple service which only purpose is to receive messages
from devices (using device-data subject) and store them into MongoDB. For
that, the bootstrapping procedure (detailed in Bootstrapping tenants) is
performed and, whenever a new message is received, it will create a new Mongo
document and store it into the device’s collection. This is shown in
Fig. 5.11.
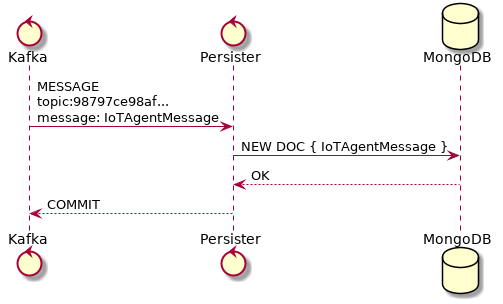
Fig. 5.11 Persister¶
This service is simple as it is by design.
5.7. History¶
History is also a very simple service: whenever a user or application sends a request to it, it will query MongoDB and build a proper message to send back to the user/application. This is shown in Fig. 5.12.
![actor User
boundary Kong
control History
database MongoDB
User -> Kong: GET /device/history/efac?attr=temperature\nHeaders="Authorization: JWT"
activate Kong
Kong -> Kong: authorize
Kong -> History: GET /history/efac?attr=temperature\nHeaders="Authorization: JWT"
activate History
History -> MongoDB: db.efac.find({attr=temperature})
MongoDB --> History: doc1, doc2
History -> History: processDocs([doc1, doc2])
History --> Kong: OK\n{"efac":[\n\t{"temperature" : 10},\n\t{"temperature": 20}\n]}
deactivate History
Kong -> User: OK\n{"efac":[\n\t{"temperature" : 10},\n\t{"temperature": 20}\n]}
deactivate Kong](_images/plantuml-8af3411e89b68e533686b708b7fd9e0b753f60b9.png)
Fig. 5.12 History¶
5.8. Data Broker¶
DataBroker has a few more functionalities than only generating topics for
{tenant, subject} pairs. It will also serve socket.io connections to emit
messages in real time. In order to do so, it retrieves all topics for
device-data subject, just as in any other component interested in data
received from devices. As soon as it receives a message, it will then forward
it to a ‘room’ (using socket.io vocabulary) associated to the device and to the
associated tenant. Thus, all client connected to it (such as graphical user
interfaces) will receive a new message containing all the received data. For
more information about how to open a socket.io connection with DataBroker,
check DataBroker documentation.
5.9. Flowbroker¶
TODO!